Summary
There is a remarkable connection between artificial reinforcement-learning (RL) algorithms and the process of reward learning in animal brains. Do RL algorithms on computers pose moral problems? I think current RL computations do matter, though they're probably less morally significant than animals, including insects, because the degree of consciousness and emotional experience seems limited in present-day RL agents. As RL becomes more sophisticated and is hooked up to other more "conscious" brain-like operations, this topic will become increasingly urgent. Given the vast numbers of RL computations that will be run in the future in industry, video games, robotics, and research, the moral stakes may be high. I encourage scientists and altruists to work toward more humane approaches to reinforcement learning.
Note: This essay is an earlier version of what became the article, "Do Artificial Reinforcement-Learning Agents Matter Morally?" The text here is fully distinct from the other article's, but several of the main ideas overlap. This piece also contains supplemental material that didn't fit within the more targeted argument of the other article.
Contents
- Summary
- Introduction
- RL and neuroscience
- Moral evaluation
- Many varieties of RL
- Standards for ethical use of RL
- Commercial uses of RL
- Emotion and RL
- Do probability updates have moral significance?
- Valence networks
- Pain vs. fear
- Gradients of agony vs. bliss
- Positive vs. negative welfare
- Should ethics discount future agent rewards?
- Why focus on RL?
- What about other optimization algorithms?
- Image classification vs. reinforcement learning: Huerta and Nowotny (2009)
- Acknowledgments
- Original article
- Appendix: A simple Q-learning example
- Footnotes
Introduction
Without pain, there would be no suffering, without suffering we would never learn from our mistakes.
Emotions can usefully be defined (operationally) as states elicited by rewards and punishers which have particular functions (Rolls 1999a, 2005a). [...] many approaches to or theories of emotion (Strongman 1996) have in common that part of the process involves 'appraisal' (Frijda 1986; Lazarus 1991; Oatley and Jenkins 1996). In all these theories the concept of appraisal presumably involves assessing whether something is rewarding or punishing.
only some cognitive capacities are associated with subjective experience, but these include [as one] good candidate [...] the internal processing of valence, seen in internal reward systems and instrumental learning.
Pleasures and pains are designed to reward and punish behaviors in order to teach an animal what to seek and what to avoid. What, then, are we to think of artificial RL in computer programs?
RL and neuroscience
There are already several excellent summaries of RL, both artificial and biological, so I won't discuss too many details here but instead refer readers to those sources for introductory reading. This piece will make more sense for those familiar with RL concepts, though many parts are understandable by a general audience as well. Feel free to skip sections if you find them confusing.
A classic textbook on RL from a computer-science perspective is Sutton and Barto, Reinforcement Learning: An Introduction. A central foundation of artificial RL is temporal difference (TD) learning. Used as a control algorithm, one basic instance of TD is Q-learning. The algorithm is simple enough that I wrote a complete example in this essay's Appendix.
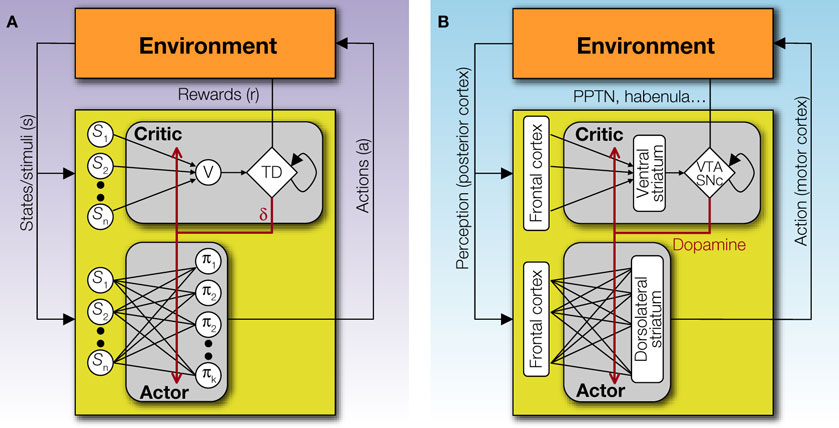
While partly inspired by biological models, artificial RL is also an elegant mathematical approach to solving Markov decision processes, which were formulated independently. It's thus remarkable that artificial RL algorithms seem to be operating within animal brains. The images in "Reinforcement learning" illustrate this powerfully.
"A Neural Substrate of Prediction and Reward" (1997) by Schultz, Dayan, and Montague explains how brains seem to implement TD:
As the rat above explores the maze, its predictions become more accurate. The predictions are considered "correct" once the average prediction error delta(t) is 0. At this point, fluctuations in dopaminergic activity represent an important "economic evaluation" that is broadcast to target structures: Greater than baseline dopamine activity means the action performed is "better than expected" and less than baseline means "worse than expected." Hence, dopamine responses provide the information to implement a simple behavioral strategy—take [or learn to take (24)] actions correlated with increased dopamine activity and avoid actions correlated with decreases in dopamine activity.
From "Understanding dopamine and reinforcement learning: The dopamine reward prediction error hypothesis" (2010) by Glimcher:
The paper by Caplin et al. (42) was important, because it was, in a real sense, the final proof that some areas activated by dopamine, the ventral striatum in particular,
can serve as a reward prediction error [RPE] encoder of the type postulated by TD models. The argument that this activation only looks like an RPE signal can now be entirely dismissed. The pattern of activity that the ventral striatum shows is both necessary and sufficient for use in an RPE system.
This article goes on to elaborate the dopaminergic learning process in the brain. I have inserted in [brackets] how this could be seen to correspond to elements of a Q-learning algorithm.
consider that neurons of the dorsal striatum form maps of all possible movements into the extrapersonal space [all actions a]. Each time that we make one of those movements, the neurons associated with that movement are active for a brief period and that activity persists after the movement is complete (48, 49). If any movement is followed by a positive prediction error, then the entire topographic map is transiently bathed in the global prediction error signal carried by dopamine into this area [Q(s,a) is augmented with a positive delta]. What would this combination of events produce? It would produce a permanent increment in synaptic strength only among those neurons associated with recently produced movements. What would that synapse come to encode after repeated exposure to dopamine? It would come to encode the expected value (or perhaps, more precisely, the expected subjective value) of the movement [Q(s,a) after learning].
What is critical to understand here is that essentially everything in this story is a preexisting observation of properties of the nervous system. We know that neurons in the striatum are active after movements as required of (the eligibility traces of) TD models. We know that a blanket dopaminergic prediction error is broadcast throughout the frontocortical-basal ganglia loops. We know that dopamine produces LTP-like phenomena in these areas when correlated with underlying activity. In fact, we even know that, after conditioning, synaptically driven action potential rates in these areas encode the subjective values of actions (48-51) [Q(s,a)'s]. Therefore, all of these biophysical components exist, and they exist in a configuration that could implement TD class models of learning.
We even can begin to see how the prediction error signal coded by the dopamine neurons could be produced. We know that neurons in the striatum encode, in their firing rates, the learned values of actions [Q(s,a)'s]. We know that these neurons send outputs to the dopaminergic nuclei—a reward prediction. We also know that the dopaminergic neurons receive fairly direct inputs from sensory areas that can detect and encode the magnitudes of consumed rewards [these are the Rt values in Q-learning]. The properties of sugar solutions encoded by the tongue, for example, have an almost direct pathway through which these signals can reach the dopaminergic nuclei. Given that this is true, constructing a prediction error signal at the dopamine neurons simply requires that excitatory and inhibitory synapses take the difference between predicted and experienced reward in the voltage of the dopamine neurons themselves or their immediate antecedents [i.e., these neurons could do the subtraction in the Q-learning formula].
RL modeling can apply to punishments as well. In "Temporal difference models describe higher-order learning in humans" (2004), the authors demonstrate that TD models predict blood activity in the ventral putamen in anticipation of pain. Predictions of punishment may happen through a different mechanism than predictions of reward:
Substantial psychological data suggest the existence of separate appetitive and aversive motivational systems that act as mutual opponents over a variety of time courses22,23. Given the (not unchallenged24) suggestion that dopamine neurons in the ventral tegmental area and in the substantia nigra report appetitive prediction error, it has been suggested that serotonin-producing neurons of the dorsal raphe nucleus, which send strong projections to the ventral striatum25, may encode aversive prediction error16. We show prediction-related responses in an area that incorporates this nucleus. There is an active debate about the involvement of dopamine in aversive conditioning26,27, and an alternative possibility is that dopamine reports both aversive and appetitive prediction errors.
Another excellent account is "Reinforcement Learning in Neural Networks" (link broken) from the course "Subsymbolic Methods in AI." Section 6 reviews how brain structures may implement an action-critic version of TD, and section 7 explains how neural networks can be used to collapse an exponentially large state space into a more constrained function for predicting the value of an input state, as in the case of TD-Gammon.
While these discoveries are astonishing, it remains unclear whether the TD approach itself is used by the brain or whether other algorithms are at play. From "Reinforcement learning":
However, only few dopaminergic neurons produce error signals that comply with the demands of reinforcement learning. Most dopaminergic cells seem to be tuned to arousal, novelty, attention or even intention and possibly other driving forces for animal behavior. Furthermore the TD-rule reflects a well-defined mathematical formalism that demands precise timing and duration of the delta error, which cannot be guaranteed in the basal ganglia or the limbic system (Redgrave et al. 1999). Consequently, it might be difficult to calculate predictions of future rewards. For that reason alternative mechanisms have been proposed which either do not rely on explicit predictions (derivatives) but rather on a Hebbian association between reward and CS (O'Reilley et al. 2007), or which use the [dopamine] DA signal just as a switch which times learning after salient stimuli (Redgrave and Gurney 2007, Porr and Wörgötter 2007). Hence the concept of derivatives and therefore predictions has been questioned in the basal ganglia and the limbic system and alternative more simpler mechanisms have been proposed which reflect the actual neuronal structure and measured signals.
Regardless, RL algorithms of some kind are at play in our brains, and based on progress so far, it may be only a matter of time until they're understood in detail.
Note that I would actually prefer for these neuroscience discoveries to come slower, in order to give more time to sort out philosophical, normative, and legal frameworks for dealing with the ethical issues they raise. But given that these advances are happening at a rapid pace, we should do the best we can to grapple with them now.
Moral evaluation
The preceding discussion may begin to raise ethical questions. Suppose the human brain does use TD for RL. Would it then be a moral issue to run an artificial TD algorithm? The program in the Appendix uses only positive reward weights, but what about programs that use negative weights on everything except the end state (c.f., Example 4.1 from Sutton and Barto)? Would this be an ethical catastrophe? We need to decide whether learning has ethical significance or whether pleasure and pain derive their moral importance from other features. Or maybe there's a combination of factors for moral relevance of which learning is just one.
Learning does not equal liking
One important observation is that learning seems to be a distinct process in the brain from liking. Berridge and Kringelbach, "Building a neuroscience of pleasure and well-being" (2011):
Mesolimbic dopamine was long regarded as a pleasure neurotransmitter (Wise 1985), but now is increasingly thought by many neuroscientists to fail to live up to its pleasure label. One line of evidence against a pleasure-causing role is that mesolimbic dopamine neurons are not always reliably activated by pleasure as such, but instead by predictive, motivational, or attentional properties rather than hedonic properties of reward stimuli (Redgrave and Gurney 2006; Salamone et al. 2007; Schultz et al. 1997). Another line of evidence has been causal, such as observations that specific manipulation of dopamine either up or down always alters motivation 'wanting' for rewards but often fails to shift pleasure 'liking' reactions to the same rewards in either animals or humans (Berridge 2007; Leyton 2010; Smith et al. 2011).
Learning does not equal consciousness
Much of the learning that takes place in animals is unconscious. As one article explains:
Many of the mundane skills that we apply every day, such as buttoning up a shirt or playing an instrument, comprise a sequence of discrete movements that must be carried out in the correct order. Scientists have long known that there are two learning systems for such patterns of movement; with the implicit system, we learn without being aware of the fact and without conscious training, such as through simple repetition.
(Question: Is this all done through RL or are other mechanisms involved?) Model-free RL is a classic case of learning cues and habits of which we may not be fully conscious.
Consciousness seems to entail more than what happens in a basic RL algorithm, although exactly what that is remains a subject of investigation. There is a vast literature aiming to provide criteria for what "consciousness" should mean, and what it might look like in machines. Rather than reviewing the literature here, I'll just mention that "A Computational Model of Machine Consciousness" is one starting point with many other references on this topic from an AI perspective. For instance, it cites
- "Axioms and Tests for the Presence of Minimal Consciousness in Agents" as proposing five important facets of consciousness: "embodiment and situatedness, episodic memory, attention, goals and motivation, and emotions" (p. 2)
- Conversations with Neil's Brain: The Neural Nature of Thought and Language as proposing that "consciousness refers to focusing attention, mental rehearsal, thinking, decision making, awareness, alerted state of mind, voluntary actions and subliminal priming, concept of self and internal talk." (p. 3)
In The Feeling of What Happens, pp. 23-24, Antonio Damasio suggests:
But on their own, without the guidance of images, actions would not take us far. Good actions need the company of good images. Images allow us to choose among repertoires of previously available patterns of action and optimize the delivery of the chosen action—we can, more or less deliberately, more or less automatically, review mentally the images which represent different options of action, different scenarios, different outcomes of action. We can pick and choose the most appropriate and reject the bad ones. Images also allow us to invent new actions to be applied to novel situations and to construct plans for future actions—the ability to transform and combine images of actions and scenarios is the wellspring of creativity.
Interestingly, Sutton and Barto explain a rudimentary architecture reminiscent of this principle. Called Dyna-Q, it records the experiences it has into a rudimentary world model that it then uses to simulate experience for additional learning.a As an extension of Q-learning, Dyna-Q is trivially simple, yet it seems to gesture in a stylized way at one of many additional components of higher cognition.
Conclusion
Present-day RL algorithms matter vastly less than animals because RL agents are vastly simpler and have minimal emotional self-awareness. They learn from numerical rewards, but the "reward experience" itself in these agents is barebones. Still, I think RL agents do matter to a nonzero degree, and at large scales they may begin to add up to something significant. In addition, as the algorithms are refined and combined with higher-level cognition, they will become more morally urgent.
Fortunately there is already discussion about machine welfare and robot rights. Embodied algorithms are easier to sympathize with because they have faces, move around, take up space, and in other ways trigger the "agency classifiers" in our brains. More concerning are abstract, non-embodied computations that don't have an interface to the external world but still execute the same underlying algorithms. I fear it may take longer to show the public why these machines matter also. Perhaps hooking them up to interfaces with eyes and a mouth would help. Stories and movies portraying the inner mental life of voiceless, faceless processes could also expand people's minds.
Many varieties of RL
Both neuroscientists and AI researchers have discovered many variants of RL.
Value functions
"Reinforcement Learning in Robotics: A Survey," section 2.2.1 describes the value-function approach to RL. Despite calling it the "dual form" of the optimization problem, the paper notes that value functions have been the main early method. They're very intuitive in the sense that they estimate the value of a state or state-action pair, and they appear to have a close connection with what happens in our brains. If any RL algorithms have ethical importance, presumably value-function algorithms do.
In particular, brains presumably use TD learning rather than Monte Carlo learning, although nonzero eligibility traces can be seen as intermediate between TD and Monte Carlo.
Due to the high dimensionality of state space, brains presumably use function approximators, specifically neural nets, to generalize value predictions as a function of input conditions, rather than separating each state as being wholly separate from each other state. Most realistic uses of RL do the same.
Presumably brains also use some form of hierarchical RL so that they can execute high-level actions that marshal lower-level subgoals rather than learning every micro step individually. "Reinforcement learning and human behavior," p. 94 discusses further evidence for hierarchical RL in humans.
Model-free vs. model-based
Humans appear to use both model-free and model-based RL. The model-free variety corresponds more to fast, reflexive habits and gut feelings, while the model-based approach leverages independently calculated probability estimates to compute expected utilities for various action choices. For further discussion of model-based RL models in neuroscience, see "Model-based reinforcement learning as cognitive search: Neurocomputational theories."
In model-based RL, rather than converging on a direct estimate of the value of a given state-action pair, Q(s,a), we independently model the reward given by the state-action pair, R(s,a), and the transition probabilities from this state to other states based on our action, T(s,a,s'). (See p. 5 of "Model-Based Reinforcement Learning.")
"Reinforcement Learning in Robotics: A Survey," Table 1 (p. 9) shows that most AI researchers use model-free methods, though this is not uniformly the case, and sometimes model-based methods perform better.
Policy search
"Reinforcement Learning in Robotics: A Survey," Table 2 (p. 11) shows that many other researchers use a policy-search approach to RL, rather than value functions. This is the "primal form" of the problem because it directly optimizes behavioral parameters without computing value estimates. Policy-gradient methods are often favored because they accommodate partial observability of state information, do not require a Markov assumption, can handle continuous action spaces, and have convergence guarantees ("Recurrent Policy Gradients," p. 2).
It's unclear whether animals use policy-gradient methods. Traditional neuroscience findings seem to point toward TD-type learning, and subjectively we have a strong sense of the value-function approach when assessing how good we think actions will be. On the other hand, policy search handles problems like noisy state information, and there is some evidence for policy search in brains, such as with bird-song learning and human learning of two-player games ("Reinforcement learning and human behavior," p. 97).
Some policy-gradient approaches are biologically implausible, such as using linear regression to estimate a gradient for varying policy parameters by small increments. Would we regard these abstract matrix-multiplication operations to constitute ethically significant reward/punishment?
Offline vs. online algorithms
Animals learn in an online fashion, with one new training example at a time. Some RL algorithms learn in batch mode. Is a batch of 50 learning updates at once (say, state1-action-reward-state2 tuples) ethically equivalent to 50 online learning updates? Or is the extra context of the environmental narrative relevant to our moral evaluation, such that the online instances matter more per update?
Evolutionary algorithms
RL by either value estimation or policy search requires gradient computation, which can be noisy and complicated. An alternative approach is to directly evolve neural-network weights to optimize performance. One recent example with a large parameter space was "Evolving Large-Scale Neural Networks for Vision-Based Reinforcement Learning."
These algorithms seem relevantly different from RL in their ethical dimensions. Rather than rewarding/punishing a single actor, these algorithms just evaluate the performance of random actors and discard those that don't work well. Any given actor doesn't need to "experience" the consequences. For those opposed to death, evolutionary algorithms might be more problematic than RL, while for those opposed to suffering, they may be less objectionable. Whether we would still regard the overall, abstracted hill-climbing process of evolution as ethically relevant is an interesting question.
Standards for ethical use of RL
A scientist places a small creature into a box. The creature has a pole on top of it. The pole begins to waver and tips slightly to one side. The scientist applies a small punishment to the creature. The creature moves in the direction of the tipping pole and succeeds in re-balancing it. Upon doing so, the scientist withholds further penalty. The creature is safe for now. A few seconds later, the pole begins to waver again and tilt to a different side. The scientist applies another punishment. This time the creature loses control, and the pole tips more and more. The scientist's punishments continue. The pole eventually tips so much that the creature can't rescue it. Zap! The scientist applies a massive punishment, far exceeding all the previous ones combined.
If this story described a biological creature, it would be a moral outrage. But in fact, this is a description of one of the example RL systems in the PyBrain machine-learning library. The "creature" is a rectangular box, and it's trained to move so as to balance a pole. The creature has the following reward function, which I've modified slightly for clarity:
def getReward(self):
reward = 0
if min(angles) < 0.05 and abs(position) < 0.05:
reward = 0
elif max(angles) > 0.7 or abs(position) > 2.4:
reward = -1000
else:
reward = -1
return reward
In other words, the creature is okay if its pole is very straight, punished slightly for small tilts, and punished enormously when the pole falls to the side. It never receives positive reward. And it runs through these negative-reinforcement cycles hundreds of times for training. This is all done in a few seconds on the computer of a grad student, who will run similar computations dozens of times in the course of an afternoon while debugging his program or producing performance numbers for reporting.
The story of the scientist punishing his creature sounds worse than it is. Animals are vastly more complex than the pole-balancing RL program, and punishing them for experimentation is vastly more tragic. We sneak in our anthropomorphic/zoomorphic intuitions about how humans and animals would feel if they were the pole-balancer, but these intuitions include many higher-order thoughts, reactions, and textures, all of which the RL program lacks. Yet, the RL program does capture an important piece of what's going on when an animal is punished, and to this extent it seems ethically problematic, if only to a vanishing degree for any single round of training. Added over millions of rounds of training, though, the ethical weight of negative RL programs begins to add up.
Commercial uses of RL
Industry
From "Reinforcement learning":
RL methods are used in a wide range of applications, mostly in academic research but also in fewer cases in industry. Typical application fields are:
- Systems control, e.g. learning to schedule elevator dispatching, (Crites and Barto 1996);
- Playing Games, e.g. TD-Gammon (Thesauro 1994), and
- Simulations of animal learning (simulating classical, Sutton and Barto 1981, or instrumental conditioning tasks, Montague et al 1995, simulating tropisms, Porr and Wörgötter 2003).
A quick search of {"reinforcement learning" industry} brought up many more examples, like modeling stock trading with multiple Q-learning agents or task scheduling in petroleum production using simulated SARSA agents. RL has also been suggested to optimize drug delivery.
Robotics
Robotics is one of the main fields in which RL is required, because robots are autonomous agents that need to learn to act in the world. According to "Reinforcement Learning in Robotics: A Survey" (p. 1): "The relationship between [robotics and RL] has sufficient promise to be likened to that between physics and mathematics."
Gaming
RL will likely be increasingly used for non-player characters (NPCs) in video games. A few of many publications on this topic:
- "High-level Reinforcement Learning in Strategy Games"—applies Q-learning to Civilization IV
- "Efficient Use of Reinforcement Learning In a Computer Game"—Q-learning for mobile games
- "Machine Learning in Games: The Magic of Research in Microsoft Products"—various RL techniques.
There are many papers (and videos) of RL applied to Mario players.
There are also numerous artificial life simulations, some of which may use RL.
Are present-day game AIs morally important?
Most NPC game AIs are driven by simple rules rather than learning. Some NPCs may use more complex algorithms, like A-star search for pathfinding, but not RL per se. I think RL is not very common commercially right now, but this will likely change.
Examples of games that do use simple RL include Creatures and Black & White, though it's not clear how biologically realistic are the algorithms employed; usually they seem more stylized than neurally accurate. On the other hand, if non-biological algorithms achieve the same function as biological ones, we may care about them at least to some extent; to do otherwise feels like chauvinism for the particular algorithms that happened to evolve on Earth.
Emotion and RL
This section explores further the relationship between learning and emotion. It describes a few of many AI approaches to emotion.
Actor-critic models
Some psychologists hypothesize a two-process model of learning in which one brain system evaluates the expected reward of a state, while another system learns appropriate actions (Jan Morén, "Emotion and Learning," p. 78). (The first seems to me like classical/Pavlovian conditioning: Given input stimuli, like a buzzer sound for Pavlov's dog, use a neural network to predict the value of this state, V(s).)
Morén suggests (p. 135) that this distinction, advanced by Mowrer with his two-factor theory of avoidance, resembles the actor-critic model in RL. Recent findings confirm the suitability of the actor-critic model for explaining avoidance.
It's commonly hypothesized that the brain employs some kind of actor-critic model, although there's doubt about this as well. "Actor-Critic Models of Reinforcement Learning in the Basal Ganglia: From Natural to Artificial Rats" discusses some real-world complications with naive actor-critic models. "Silencing the Critics" presents a figure illustrating a hypothesized correspondence of the actor-critic model with brain regions, with the ventral striatum playing the role of the critic. A main portion of the ventral striatum is the nucleus accumbens.
{kind=link}
 [Public domain or Public domain], via Wikimedia Commons: https://commons.wikimedia.org/wiki/File:Dopamine_pathways.svg 'Dopamine Pathways. In the brain, dopamine plays an important role in the regulation of action, emotion and cognition through its projections to the basal ganglia and cortex. In rats, dopamine selectively targets prefrontal cortex, while in primates, it innervates much of the cortex, including dense innervation of the motor cortices. Thus, the above picture of the human brain would be accurate if it were a rodent brain, but is not accurate for a primate brain, where there are extensive dopamine projections to much of the cortex. IT WOULD BE HELPFUL IF SOMEONE PUT AN ACCURATE PICTURE HERE. Dopamine cell bodies reside in the midbrain in the substantia nigra pars compacta, and in the ventral tegmental area (VTA). Some of these dopamine cells are 'Value cells' firing to reward prediction error, e.g. they increase firing to a cue that predicts reward, and decrease firing if an expected reward does not occur. Other dopamine cells are 'Salience cells' firing to both appetitive and aversive events, and likely underlie the high levels of dopamine released in prefrontal cortex during exposure to uncontrollable stress.'")
The critic is hypothesized to compute reward-prediction errors. But is this related to pleasure? Or is pleasure something different? Maybe pleasure is related to the incoming Rt rewards rather than computing the subtraction against expectations. For what it's worth, the nucleus accumbens (critic) is associated with pleasure, though it's also associated with wanting and other effects. In "Neural Coding of Pleasure," Aldridge and Berridge highlight the importance of the ventral pallidum for pleasure, rather than the ventral striatum, though they note that other regions are important as well, including the ventral striatum (or nucleus accumbens, the critic), which also contains hedonic hotspots (p. 64). So clearly the critic is related to the emotional experience of reward, though other parts of the brain are involved as well.
Emotions as intrinsic rewards
If RL uses scalar reward numbers, why don't we have just pleasure and pain at varying intensities? What about fear, boredom, anger, love, embarrassment, and dozens of other feelings?
{kind=link}
Presumably different emotions correspond to different contexts. For instance, fear is felt when your heart races, your alertness is aroused, and so on. This is different from the discomfort of nausea, which corresponds to a different set of somatic and neural activities. Different qualia of experience are distinguished by different patterns of activation alongside the scalar reward signal. Yet it remains the case that there's a (scalar) valence associated with these different emotions: Pleasure, contentment, love, excitement, hope, etc. all feel good, despite their different textures. Perhaps the textures help an organism discriminate which kind of good thing is happening to it.
One reason for the diversity of emotions is that some serve as intrinsic rewards, rather than rewards based on external stimuli. A clear example with relevance to RL is curiosity, which serves to address the RL explore-exploit tradeoff and allow the organism to learn important information for the long term. More generally, one can imagine that organisms may find it useful to generate intrinsic rewards for skill acquisition and broad learning outside of a goal-specific context. This concept is proposed in "Intrinsically Motivated Reinforcement Learning." Those authors note (p. 2) that
Recent studies [2, 3] have focused on the idea that dopamine not only plays a critical role in the extrinsic motivational control of behaviors aimed at harvesting explicit rewards, but also in the intrinsic motivational control of behaviors associated with novelty and exploration. For instance, salient, novel sensory stimuli inspire the same sort of phasic activity of dopamine cells as unpredicted rewards.
In "Emotion-Based Intrinsic Motivation for Reinforcement Learning Agents," this proposal is operationalized with intrinsic rewards for novelty, proximity to goal, familiarity, and value of the current reward relative to expectations. These are combined with raw extrinsic rewards (in this case, eating prey) in the agent's overall reward function to improve performance.
Pain asymbolia
Pain asymbolia shows that there are at least two main components to pain: (1) Detecting its presence and (2) feeling bad about it, learning from it, responding to it, etc.
In an RL framework, the "detecting" function of pain can be seen as part of determining what state the agent is in—e.g., realizing that "it's painfully cold outside." The motivational part then corresponds to learning and action selection—e.g., don't go outside when it's painfully cold, and choose an action to reduce your coldness, like going back inside. Note that the emotional "suffering" response to pain is more than just learning; it also includes emotional awareness of the painfulness and motivation to take actions that may have already been learned to reduce pain.
Other AI versions of RL emotion
A number of AI researchers have developed emotion-like RL algorithms. Some fall outside the standard mathematical framework of Sutton and Barto, though many of the principles are similar, as may be the ethical evaluations.
MicroPsi
Joscha Bach's "A Motivational System for Cognitive AI" describes the MicroPsi framework of agents exhibiting emotion-type cognitive processes. For example, the agents have needs (food, water, social support, learning) and select actions to fulfill those needs. Fulfilling desires by action selection seems like motivation ("wanting"), but since wanting and liking are distinct, this may not imply hedonic experience ("conscious liking"). Bach actually makes a similar observation on p. 239:
Whenever the agent performs an action or is subjected to an event that reduces one of its urges, a reinforcement signal with a strength that is proportional to this reduction is created by the agent's "pleasure center". The naming of the "pleasure" and "displeasure centers" does not necessarily imply that the agent experiences something like pleasure or displeasure. Like in humans, their purpose lies in signaling the reflexive evaluation of positive or harmful effects according to physiological, cognitive or social needs. (Experiencing these signals would require an observation of these signals at certain levels of the perceptual system of the agent.) Reinforcement signals create or strengthen an association between the urge indicator and the action/event. Whenever the respective urge of the agent becomes active in the future, it may activate the now connected behavior/episodic schema. If the agent pursues the chains of actions/events leading to the situation alleviating the urge, we are witnessing goal-oriented behavior.
Conversely, during events that increase a need (for instance by damaging the agent or frustrating one of its cognitive or social urges), the "displeasure center" creates a signal that causes an inverse link from the harmful situation to the urge indicator. When in future deliberation attempts (for instance, by extrapolating into the expectation horizon) the respective situation gets activated, it also activates the urge indicator and thus signals an aversion. An aversion signal is a predictor for aversive situations, and such aversive situations are avoided if possible.
So the MicroPsi architecture uses something like RL as a component, but within a broader context.
Holland's classifier system
In "Reinforcement Learning and Animat Emotions," Ian Wright describes Holland's classifier system, which uses chains of production rules to implement state-action pairs, with the "if" clause representing the state and the "then" clause representing the action. Rules "bid" to be chosen, and chosen rules are reinforced based on whether their action was good or bad. Rules can form long chains, so-called "bucket brigades," and then credit is propagated backwards through these layers. This accomplishes a similar purpose as eligibility traces in TD learning. In addition to direct RL, populations of rules may be evolved.
Wright draws analogy between credit (reward) in the classifier system and money in an economy. My assumption is that a rule's bid reflects the expected reward, and if actual reward is higher, the bidder makes a profit. In fact, the analogy between neural value estimation and economic currency has been made by other authors—see "Neural Economics and the Biological Substrates of Valuation." Wright notes that this currency allows individual classifiers to "buy" processing power (i.e., be selected by the organism). This raises the question of whether the economy itself has intrinsic ethical significance. For instance, when it's reported that a stock price has risen above the price someone paid for it, is this like a brain squirting dopamine due to the actual reward exceeding expectations?
Wright suggests that what makes the valence of the reward signal conscious is its being hooked up to other self-monitoring systems in the organism. (Likewise, I might add, financial gains and losses are monitored by other parts of the economy.)
Do probability updates have moral significance?
Let Q(s,a) represent the learned value of a state-action pair (s,a). In model-free Q-learning, upon observing a new transition from one state-action pair (s,a) to another state s' during which a reward r is earned, the agent updates as follows:
new estimate of Q(s,a) = weighted average between [old estimate of Q(s,a)] and [r + (discounted Q-value of s' if agent chooses the best action once getting there)].
My current best guess of how this relates to emotion in the human brain is that pleasure/pain happens when the brain receives and broadcasts the news about the new reward r. One of the regions to which this signal is broadcast is the basal ganglia, where the Q-learning update as specified in the above equation can happen.
Now consider model-based RL as described here. In this case, the agent maintains explicit estimates both of the average reward R(s,a) of choosing action a in state s, as well as the transition probability T(s, a, s') of moving from s to s' if the agent chooses action a. Given a new observation that choosing action a in state s led to reward r and next state s', the agent updates:
new estimate of R(s,a) = weighted average between [old estimate of R(s,a)] and r
new estimate of T(s,a,s') = weighted average between [old estimate of T(s,a,s')] and 1
new estimate of T(s,a,s'') = weighted average between [old estimate of T(s,a,s'')] and 0, for every s'' not equal to s'.
Given these estimates the agent can compute Q more explicitly than in the model-free case:
new estimate of Q(s,a) = R(s,a) + discount * Σs' [T(s,a,s') * Q-value given that agent goes to s' and then chooses the best response once there].
With this setup, we can once again interpret pleasure/pain as the broadcasting of a new reward r. But now there's another factor at play also: updates to our transition probabilities T. What should we make of those? Do they have moral significance? I'm not sure.
The kind of model-based RL depicted by the equation above is still extremely crude, but it could be expanded in various ways, such as
- looking ahead more than one step in computing expectations
- more sophisticated updates to reward estimates and more sophisticated Bayesian updating of probability estimates
- updating beliefs and reward estimates based not just on personal experience but also observation of others, gossip, reading, logical deduction, etc.
Valence networks
My best guess for a reasonable neural referent of "conscious pleasure" is the broadcasting of a reward signal r throughout the brain combined with the sundry after-effects thereof.
Rolls (2008), p. 135: "emotions normally consist of cognitive processing which analyses the stimulus, and then determines its reinforcing valence; and then an elicited mood change if the valence is positive or negative."
Rolls (2005) (pp. 408, 415):
emotion [...] in primates is not represented early on in processing in the sensory pathways [...] but in the areas to which these object analysis systems project, such as the orbitofrontal cortex, where the reward value of visual stimuli is reflected in the responses of neurons to visual stimuli [...].
damage to the orbitofrontal cortex renders painful input still identifiable as pain, but without the strong affective, 'unpleasant', reaction to it.
In recent neuroimaging studies of the cortical networks that mediate hedonic experience in the human brain, the orbitofrontal cortex has emerged as the strongest candidate for linking food and other types of reward to hedonic experience. The orbitofrontal cortex is among the least understood regions of the human brain, but has been proposed to be involved in sensory integration, in representing the affective value of reinforcers, and in decision making and expectation.
the orbitofrontal cortex is involved in representing negative reinforcers (punishers) too, such as aversive taste, and in rapid stimulus–reinforcement association learning for both positive and negative primary reinforcers.
Rolls (2008), p. 150: "It is also of interest that reward signals (e.g. the taste of food when we are hungry) are associated with subjective feelings of pleasure (Rolls 2005a, 2006a). I suggest that this correspondence arises because pleasure is the subjective state that represents in the conscious system a signal that is positively reinforcing (rewarding)". Rolls (2008) adopts a higher-order theory of qualia in which there are unconscious reward signals, and consciousness of them consists in higher-order syntactic thoughts about the reward signals. Page 151: "the arguments I have put forward above suggest that we are conscious of representations only when we have high-order thoughts about them. The implication then is that pathways must connect from each of the brain areas in which information is represented about which we can be conscious, to the system which has the higher-order thoughts". Given this view, Rolls would certainly disagree with attributing qualia to simple artificial RL agents. My opinion, in contrast, is that even if one holds a higher-order theory of consciousness, "higher-order reflection" is fuzzy and comes in degrees (Tomasik 2014), and simple RL agents have tiny but nonzero degrees of "higher-order reflection".
Ole Martin Moen has written a more philosophical account of pleasure, in which he concludes that "pleasure and pain have the ontological status as opposite sides of a hedonic dimension along which experiences vary." I would omit the word "ontological" here, but I do suspect that experiences acquire valence from valence networks that compute the magnitude of a reward and then distribute this information to have further downstream effects. (I think this view is roughly comparable to one that Moen rejects—namely, the presence of many "hedonometers" that evaluate the valence of various input stimuli or internal somatic events.)
What separates valence vs. non-valence networks?
In "Do Artificial Reinforcement-Learning Agents Matter Morally?", I mentioned how Parkinson's disease appears to impair human RL abilities. I noted that we still care about Parkinson's patients even if their RL isn't as pronounced as in normal individuals. In the limit where an organism has no RL but only fixed behavioral patterns, it still seems to me that the organism matters morally to some degree.
If, as I also suggested in that paper, "pleasure" is more properly associated with broadcast of a valenced reward signal r than with the RL process that happens by comparing r against expectations, this might also seem to suggest that RL isn't the crucial feature of hedonic experience; rather, the valence network that generates the reward signal would be.
The function-approximating neural network that computes the predicted value of a state or state-action pair is different from the neural network that computes the reward of stimuli:

The above figure is obviously stylized but may not be entirely unrealistic? This article reports: "a cell has been isolated that responded to the taste of glucose (but not other foods or fluids) and did so only when the animal was food deprived [...] (Rolls, 1976)." An oversimplified interpretation might suggest that the glucose-responsive neuron is like the output of the neural network on the left (though specific to glucose rather than responding to all types of food)??
This article on the orbitofrontal cortex (OFC) explains:
the OFC seems to be important in signaling the expected rewards/punishments of an action given the particular details of a situation.[6] In doing this, the brain is capable of comparing the expected reward/punishment with the actual delivery of reward/punishment, thus, making the OFC critical for adaptive learning. This is supported by research in humans, non-human primates, and rodents.
But what morally distinguishes a valence network from any other neural network (or indeed, from any other signal of any type)? They all just pass along information. Presumably the answer is that a valence network only counts as a valence network in virtue of what its output does. Where neurons are concerned: You are who you know and how you influence them. One of these roles of a valence network is to feed into RL. Of course, the network presumably has other functions too, such as feeding into verbal thoughts, planning, motor responses, the endocrine system, and so on. So presumably an agent that lacks RL can still have something akin to valence in virtue of these other components. I would conjecture that the valence networks of severe Parkinson's patients presumably remain mostly intact.
But we shouldn't blindly attribute valence to any network (or other process) that produces output based on its input. Hedonic tone comes from the suite of functions that a valence network triggers. So, for instance, I'm doubtful that deep image-classification neural networks should be considered significantly valenced.
LeDoux and Brown (2017) seem to generally agree with my contention that context from other brain and body processes determines whether a given cognitive state is emotional. They ask what the difference is between "your personal knowledge that there is a pencil present and that it is you that is looking at this pencil" and "there is a snake present and you are afraid it may harm you". The authors explain:
Activation of defensive circuits during an emotional experience results in various consequences that provide additional kinds of inputs to working memory, thus altering processing in the [... cortically based general networks of cognition] GNC in ways that do not occur in nonemotional situations [...]. For one thing, outputs of the amygdala activate arousal systems that release neuromodulators that affect information processing widely in the brain, including in the GNC. Amygdala outputs also trigger behavioral and physiological responses in the body that help cope with the dangerous situation; feedback to the brain from the amygdala-triggered body responses (as in Damasio) also change processing in many relevant circuits, including the GNC, arousal circuits, and survival circuits, creating loops that sustain the reaction. In addition, the amygdala has direct connections with the sensory cortex, allowing bottom-up attentional control over sensory processing and memory retrieval, and also has direct connections with the GNC. These various effects on the GNC may well influence top-down attentional control over sensory processing, memory retrieval, and other cognitive functions. The GNC is also important in regulation over time of the overall brain and body state that results from survival circuit activation [...].
Pain vs. fear
Suppose that when you go to the dentist, you're served by one of two possible assistants: one who works on teeth gently/carefully and one who works aggressively/sloppily. Let s be the state of standing outside the dentist's office. You take action a to tell the receptionist you're ready. Suppose this process has no intrinsic reward r. Soon you're directed to your dentist chair, and it turns out you got the sloppy assistant. This is your new state s', which has a low best-response Q-value. In other words, in state s', future possibilities look unpleasant, even though you haven't yet endured any pain. How should we characterize this emotionally? Based on my subjective imagination of the situation, it seems the transition from s to s' is one that would evoke fear (anticipation of future pain). Obviously this is oversimplified. In human brains, these updates are accompanied by lots of corresponding changes in attention, arousal, muscle responses, memories, and the like. This is why our experiences of pain or fear are rich and complex. But this identification seems very crudely appropriate.
In general, I would suggest the following rough picture for the emotional character of different RL variables:

Rolls (2008) seems to suggest the same idea (p. 134): "fear is an emotional state which might be produced by a sound (the conditioned stimulus) that has previously been associated with an electric shock (the primary reinforcer)." In the presence of a sound predicting shock (which is a state s' similar to the sloppy dentist), even your best-response Q-value will be low.
Gradients of agony vs. bliss
David Pearce's Hedonistic Imperative proposes that organisms of the future could be motivated by "gradients of bliss" rather than the Darwinian pleasure/pain axis. To put it crudely, rather than a hedonic scale from -10 to 10, it would be a scale from 80 to 100—all positive experiences, but some more positive than others to maintain learning and motivation.
I'm skeptical that this could work as well as David hopes. In "Why Organisms Feel Both Suffering and Happiness," I observe that we suffer in response to damaging stimuli because it's easier for evolution to build in aversive feelings for specific noxious experiences than to make all other experiences extremely positive except for the damaging ones. For instance, suppose a bunny feels +1 for a day of eating grass and -10000 for being eaten by a fox. In order to transform this to gradients of bliss, the bunny would have to feel 10001 for eating grass, 10000 for neutral experience, and 0 for being eaten.
One other observation suggested by this discussion is that the scale of reward numbers doesn't matter. {1000, 999, 0} is equivalent to {1, .999, 0}, which is equivalent to {1000000, 999000, 0}. From the standpoint of the algorithm, these are just symbols that represent which tradeoffs to make. This illustrates the thesis that there's no objective way to make interpersonal comparisons of utility. An agent with rewards in [-10,2] may seem more important than one with rewards in [-1,.2], but the latter could just as well be written with rewards in [-1000,200] with no change whatsoever to the meaning or operation of the algorithm. This point is one reason I'm wary of assuming that bigger brains matter more than smaller ones: To the small brain, it is the whole world, and its utilities could be scaled arbitrarily. That said, if rewards can only come in discrete quanta, then a bigger brain has more possible reward values, so it seems plausible to imagine its utility scale to be "objectively bigger" in some sense. For instance, if we represented all utilities as integers, then the most compact integer representation would have higher max and lower min values for a brain with more quanta, other things being equal.
Positive vs. negative welfare
In the main version of this article, I puzzled over the distinction between when an RL agent is experiencing positive vs. negative welfare. This question is particularly tricky for an agent with a fixed (finite or infinite) lifespan whose behavior is identical with respect to a uniform shift of all reward values up or down. I offered a few ideas about how we might guess whether a simple agent should be said to be happy or suffering.b
I'm not particularly troubled by the fact that rewards can be made positive or negative arbitrarily by adding a constant to all of them, because I think happiness should be thought of more holistically than as being just the sign of a single number. Rather, happiness is the collection of responses that an organism has to beneficial stimuli. Happiness is complex and requires "hedonic work".
Moreover, happiness is not a "real" quantity that exists "out there". As with many other questions about consciousness, this quandary becomes less confusing when we adopt an eliminativist position on qualia. "Pleasure" and "pain" aren't objective states of the universe, and so neither is the distinction between them. It's not the case that an objective quale of positive or negative valence supervenes on, say, a pole-balancing RL agent. Rather, the agent just does what it does, and we attribute emotions to it. "Pleasure" and "pain" are labels that were originally conceived in the context of a complex organism like a human, and for human minds, many varieties of emotional texture and evaluative judgment overlay our experiences. Our human notions of pleasure and pain may also include some arbitrary noise due to historical accidents of neurobiology, language, and culture. When extending our concepts to a simpler agent, we have to decide which kinds of algorithms are positive vs. negative in a system whose simplicity renders the anthropomorphic bifurcation between the two types of emotional valence not completely coherent.
Here's an example to illustrate what I mean. Compare the concept "happiness" to the concept "chair" and the concept "suffering" to the concept "table". In human consciousness, we can usually distinguish happiness from suffering pretty well, just like in human homes we can usually distinguish chairs from tables pretty well. However, sometimes the boundary between the concepts is blurry, especially when the object under consideration is simple. For example, is a wood stump a chair or a table? If you lay a tablecloth on it, it becomes more like a table, while if you sit on it, it becomes more like a chair. And if you don't do either of those things, maybe it's not very chair-like or table-like at all. How about a waterfall? Is that a chair or a table? A waterfall doesn't seem match the concept of "chair" or "table" very well. In a similar way, one could argue that a simple reinforcement-learning agent doesn't need to map very well onto either the concept of "happy" or the concept of "suffering", even if one feels that such an agent does have some degree of ethically relevant motivation and preferences.
One last observation on this topic is that in animals, some receptors signal only good or only bad things. For instance, nociceptors that signal pain may only convey bad news to the brain. Meanwhile, sweetness receptors usually signal good news to the brain. So it makes sense people would develop distinctions between "good" vs. "bad". For instance, "bad" is like touching a flame, and "good" is like eating candy. And while heat can come in degrees of painfulness, while sugar can come in degrees of sweetness, given that the two sensations are perceived via different peripheral-neuron systems, maybe it makes some sense that there's a natural boundary between very mild burning heat on the pain side of things and very mild sweet tastes on the pleasure side of things. The gap in the middle is what we call the neutral point.
See also: "Why Organisms Feel Both Suffering and Happiness".
Should ethics discount future agent rewards?
"Reinforcement Learning in Robotics: A Survey," section 2.1 explains that RL agents typically use one of three mechanisms to aggregate future rewards:
- Undiscounted sum of rewards over a finite time horizon H: Σt=0H Rt
- Exponentially discounted sum of rewards over an infinite horizon, with discount factor γ: Σt=0∞ γt Rt
- Average undiscounted reward over an infinite horizon: limH → ∞ (1/H) Σt=0H Rt.
Different methods may be appropriate for different tasks. The discounted infinite horizon is the classic textbook case, but in practice it can yield short-sighted and unstable solutions. Meanwhile, the infinite-average approach can lead to irregular behavior in the short run because the algorithm only cares about optimizing the "far future." We can see parallels between these engineering issues and philosophical debates about intergenerational ethics.
Animals discount the future because of uncertainty: It's not clear if the conditions they observed in the past will obtain in the long term, or if they'll even be around in the long term, so it's safer to grab the reward now. Economists discount the future also because of the possibility of return on investment from money available today. Some thinkers propose a third form of discounting: intrinsically valuing the future less, just because people today intuitively don't care as much about it. I think intrinsic discounting of future welfare is wrong, and when people feel the future matters less, they're probably either being selfish or else illicitly incorporating intuitions about discounting based on uncertainty or investment. Future organisms already exist in our block universe, and time is just one of four dimensions of space-time. It seems absurd to discount based on spatial distance (though sadly, some philosophers have advocated this too).
Suppose we have an RL agent that maximizes a discounted sum of future rewards. Should we also discount the ethical value of its future rewards on intrinsic grounds (ignoring uncertainty, etc.)? The intuition against intrinsic discounting says "no." An experience is an experience no matter when experienced, so it counts equally. On the other hand, the agent itself would be willing to trade away more reward later for less now, and this is more than just short-term selfishness, because its future self would agree that such trades were right to have been made. Our ethical assessment differs from its personal preferences. Maybe one way out of this dilemma is to suggest that the agent is discounting future rewards in an effort to deal with uncertainty, and if it had certainty that the future would continue to be like the past and that it would still be alive in the future, it would no longer want to discount. Thus, if we know due to our superior understanding of the code that it needn't discount the future on uncertainty grounds, we can rightly override its apparent preference. (Of course, there's never complete certainty. The laptop on which the agent is running might crash, in which case the agent would have been right to prioritize shorter-term rewards after all.)
Why focus on RL?
Ian Wright's "Reinforcement Learning and Animat Emotions" makes an important observation (p. 13): RL-based views of emotion are different from past attempts to model emotions in simulated creatures because with RL, emotion falls out of the design itself. It explains why organisms feel happiness and suffering. Those emotions don't have to be appended on without purpose, the way one might tape wings onto a ball in an effort to make it into a bird. RL provides an overarching framework that allows us to understand emotion from many perspectives: Evolutionary purpose, algorithmic implementation, neural anatomy, and phenomenological experience.
It's clear that the valence of emotions is fundamentally tied with RL. Exactly how, and exactly what parts of the algorithms are most morally relevant, remain to be clarified. Consciousness is another important piece of the puzzle, and perhaps there are others.
What about other optimization algorithms?
At a high level, RL involves a system
- aiming to maximize a function, the sum of discounted future rewards:
Σt (discount)t (rewardt)
- by observing one component of the function at a time: rewardt
- and adjusting behavioral parameters in response to the new information.
We can see this same kind of dynamic in many algorithms that are not normally thought of as RL.
Non-RL learning algorithms
A very simple example is the perceptron. It
- aims to maximize a function, the negative sum of classification errors:
-Σt |right_answert - guesst|
- by observing one component of the function at a time: right_answert
- and adjusting prediction parameters in response to the new information.
One quibble in this comparison is that typically a perceptron learns on a fixed training set, aiming to minimize the error on that set by cycling through the data on multiple rounds. In contrast, an RL agent passes through each training example just once, and it aims to maximize reward over the whole history, not just on a fixed set of experiences. But we could imagine running the perceptron on an infinite set of data drawn from some distribution, in which case its learning would more closely resemble RL.
In this analogy, -|right_answert - guesst| is the "punishment" that the system experiences at step t. If news of this value were broadcast throughout the rest of the system's "brain," triggering other sorts of cognitive responses, would this correspond to "conscious experience" of the punishment?
Like an RL system, a perceptron receives information about its current state (in the form of a feature vector), takes an action (i.e., gives a prediction score), and receives a signal about the quality of that action.
This kind of online parameter optimization to minimize error is common to a number of learning algorithms, including larger neural nets, boosted decision trees, and many other real-world systems.
As we asked before with online vs. batch RL, we might also ask whether batch non-RL learning algorithms would matter less than online ones. In batch algorithms we may use matrix multiplication rather than point-by-point updates. We might also employ a Hessian matrix to accelerate convergence. How do these factors play into a moral evaluation?
General function optimization?
What about generic function optimization, like Newton's method, gradient descent, or genetic algorithms? These too involve optimizing a function (though not necessarily a sum of error terms) by observing a current value and then adjusting parameters with the aim of increasing this value.
Note that our answer here has implications for how we view certain variations of RL, like policy search and evolutionary algorithms. While the individuals in an evolutionary framework don't learn, one could see the system as a whole as learning with reinforcement, in the sense that the system tries various options (various actions) and picks (reinforces) those that perform the best.
Image classification vs. reinforcement learning: Huerta and Nowotny (2009)
Huerta and Nowotny (2009) is a fascinating paper that implements a biologically plausible neural-network model of learning by the insect brain, especially the mushroom bodies (MBs). The neural network learns by reward signals, inspired by "the existence of giant reward neurons that send massive inputs to many parts of the insect brain, including the MBs (Hammer & Menzel, 1995)" (p. 2132).
Even though the network's learning is based on reinforcement, the authors apply their neural network to the task of classifying handwritten digits. But isn't that just a "boring" classification task rather than a potentially morally relevant reinforcement task? On closer inspection, we see that there's not a big difference. We can think of digit classification as a reinforcement task where you get rewarded for predicting the correct digit. Alternatively, we can think of reinforcement learning as a classification problem: given the current state of the world, identify the best action to take among the set of actions.
Huerta and Nowotny (2009) use Hebbian learning, the most basic form of which is that if the strongest-firing output neuron (representing a digit 0 through 9) is correct, then for each input neuron connecting to that output neuron, if the input neuron also fired, the connection weight is strengthened (with some probability), while if the input neuron didn't fire, the connection weight is weakened (with some probability) (pp. 2132-33). I interpret this as the output neuron basically saying to the input neurons: "My firing was the right thing to do for this pattern of inputs. If you as an input neuron also fired, then your firing is a predictor that I should fire, so I strengthen my connection with you, so that if you fire, I'm more likely to fire. If you didn't fire this time around, then a future situation where you do fire won't be a good predictor that I should fire (maybe it would instead predict that some other output should fire), and I weaken my connection to you." Or put another way, the output neuron says: "It was a good decision for me to fire in this case. For those of you input neurons who advised me to fire, I'll trust your advice more. Those input neurons who didn't advise me to fire were wrong, so I'll trust you less going forward."
Later, Huerta and Nowotny (2009) also add negative reinforcement in which, if the highest-scoring digit-classification neuron is wrong, then whatever input neurons to that output neuron fired have their connections to the output neuron weakened (with some probability) (pp. 2137-38). Here the output neuron is saying: "For this pattern of inputs, we should fire less strongly, so the input neurons who positively contributed to my firing should be connected to me less strongly." Or: "You input neurons who told me to fire were wrong; I'm going to trust you less next time." Huerta and Nowotny (2009) explain (p. 2138):
We expect the additional mechanism of negative reinforcement to help disambiguate confusing inputs. The simulations show that this expectation is correct. The additional negative reinforcement improves the final performance [...]. Furthermore, it becomes important only in late stages of the training. At the beginning, the performance is almost unchanged but continues to improve with respect to the previous evolutions.
Acknowledgments
The potential ethical significance of RL is an idea I first learned from Carl Shulman.
Original article
The first draft of this article was "Humane Reinforcement-Learning Research" on Felicifia.
Appendix: A simple Q-learning example
Program code
The following program can be run in R. It implements a very basic Q-learning algorithm. For simplicity, I didn't use eligibility traces, though it seems biological brains may use them ("Dopamine Cells Respond to Predicted Events during Classical Conditioning: Evidence for Eligibility Traces in the Reward-Learning Network" by Pan, Schmidt, Wickens, and Hyland).
# Learning to get home on a one-dimensional sidewalk.
# by Brian Tomasik
# 4 July 2013
# Initialize settings.
sidewalkLen = 10
learningRate = 0.05
discount = 0.95
chanceDoSuboptimalThing = 0.1
LEFT = 1
RIGHT = 2
numDirections = 2
expectedReward = matrix(0,numDirections,sidewalkLen)
rewards = matrix(0,1,sidewalkLen)
rewards[1,sidewalkLen] = 10 # Home is where the heart is.
# Walk home several times, learning the way better each time.
numTimesWalkHome = 10
for(t in 1:numTimesWalkHome){
position = 1
gotHome = FALSE
numStepsThisTime = 0
# Take a new step and update expectations.
while(!gotHome) {
# Go left or right?
inclinationToGoLeft = expectedReward[LEFT,position]
inclinationToGoRight = expectedReward[RIGHT,position]
rand = runif(1,0,1)
oldPos = position
nextDirectionToWalk = 0
if(inclinationToGoLeft == inclinationToGoRight) {
if(rand < 0.5) { nextDirectionToWalk = LEFT }
else { nextDirectionToWalk = RIGHT }
}
else if(inclinationToGoLeft > inclinationToGoRight || rand < chanceDoSuboptimalThing * log(10)/log(t+10)) {
nextDirectionToWalk = LEFT
}
else {
nextDirectionToWalk = RIGHT
}
# Move.
if(nextDirectionToWalk == LEFT) { position = max(1,position-1) }
if(nextDirectionToWalk == RIGHT) { position = min(position+1,sidewalkLen) }
# Update expectations.
bestExpectationsFromNextMove = max(expectedReward[LEFT,position], expectedReward[RIGHT,position])
dopamine = rewards[1,position] + discount * bestExpectationsFromNextMove - expectedReward[nextDirectionToWalk,oldPos]
expectedReward[nextDirectionToWalk,oldPos] = expectedReward[nextDirectionToWalk,oldPos] + learningRate/log(t+10) * dopamine
numStepsThisTime = numStepsThisTime + 1
if(position == sidewalkLen) { gotHome=TRUE }
}
# Report on this round.
print(sprintf("Yay, I got home in %d steps!",numStepsThisTime))
print("expectedReward = ")
print(expectedReward)
for(i in 1:2) { print("") }
}
A sample run
In the following output, the first row of the 2 x 10 matrix shows the expected value of going left at that position and the second row shows the expected value of going right. You can see how the value "oozes" down from the reward at the bottom right (not shown in the matrix). Due to this oozing, the agent can follow its nose along the bottom path (i.e., going right rather than left along the sidewalk).
[1] "Yay, I got home in 109 steps!"
[1] "expectedReward = "
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0 0 0 0 0 0 0 0 0.0000000 0
[2,] 0 0 0 0 0 0 0 0 0.2085162 0
[1] ""
[1] ""
[1] "Yay, I got home in 91 steps!"
[1] "expectedReward = "
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0 0 0 0 0 0 0 0.000000000 0.0000000 0
[2,] 0 0 0 0 0 0 0 0.003985872 0.4055353 0
[1] ""
[1] ""
[1] "Yay, I got home in 85 steps!"
[1] "expectedReward = "
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0 0 0 0 0 0 0.00000e+00 0.00000000 0.00055374 0
[2,] 0 0 0 0 0 0 7.38139e-05 0.02585114 0.59256564 0
[1] ""
[1] ""
[1] "Yay, I got home in 66 steps!"
[1] "expectedReward = "
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0 0 0 0 0 0.000000e+00 0.0000000000 0.00000000 0.00055374 0
[2,] 0 0 0 0 0 1.328565e-06 0.0005377062 0.03602686 0.77080039 0
[1] ""
[1] ""
[1] "Yay, I got home in 34 steps!"
[1] "expectedReward = "
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0 0 0 0 0.000000e+00 0.000000e+00 0.0000000 0.00000000 0.00055374 0
[2,] 0 0 0 0 2.330343e-08 1.073556e-05 0.0011597 0.04888174 0.94120342 0
[1] ""
[1] ""
[1] "Yay, I got home in 13 steps!"
[1] "expectedReward = "
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0 0 0 0.000000e+00 0.000000e+00 0.000000e+00 0.000000000 0.00000000 0.00055374 0
[2,] 0 0 0 3.992344e-10 2.068048e-07 3.040994e-05 0.001976228 0.06412492 1.10456693 0
[1] ""
[1] ""
[1] "Yay, I got home in 19 steps!"
[1] "expectedReward = "
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0 0 0.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00 0.000000000 0.00000000 0.00055374 0
[2,] 0 0 6.693331e-12 3.859358e-09 7.129905e-07 6.300557e-05 0.003016433 0.08151178 1.26155181 0
[1] ""
[1] ""
[1] "Yay, I got home in 9 steps!"
[1] "expectedReward = "
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0 0.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00 0.0000000000 0.000000000 0.0000000 0.00055374 0
[2,] 0 1.099973e-13 7.000174e-11 1.550979e-08 1.736082e-06 0.0001114873 0.004303807 0.1008339 1.41271659 0
[1] ""
[1] ""
[1] "Yay, I got home in 12 steps!"
[1] "expectedReward = "
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00 0.000000000 2.888028e-06 0.0000000 0.00055374 0
[2,] 1.774489e-15 1.237405e-12 3.190186e-10 4.325307e-08 3.505127e-06 0.000245413 5.857387e-03 0.1219117 1.55853866 0
[1] ""
[1] ""
[1] "Yay, I got home in 9 steps!"
[1] "expectedReward = "
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0.000000e+00 0.000000e+00 0.0000e+00 0.000000e+00 0.000000e+00 0.0000000000 2.888028e-06 0.000000 0.00055374 0
[2,] 2.136503e-14 6.275076e-12 9.9951e-10 9.810806e-08 7.337867e-06 0.0003341911 7.692643e-03 0.144589 1.69943011 0
Updates per second
On my laptop, 100K iterations of this algorithm take 51 seconds and result in 930K learning updates, or 18K per second. I don't know how many updates per second a human does, but it's probably fewer than this. Of course, even if this RL program were conscious and even if we cared about its learning updates in addition to its hedonic experience, we might give it less moral weight per update than for more complicated humans. Still, the scale of potential RL computation, now and especially in the future, is vast. ↩ ↩
Footnotes
- Sutton and Barto, section 9.1:
The heart of both learning and planning methods is the estimation of value functions by backup operations. The difference is that whereas planning uses simulated experience generated by a model, learning methods use real experience generated by the environment. Of course this difference leads to a number of other differences, for example, in how performance is assessed and in how flexibly experience can be generated. But the common structure means that many ideas and algorithms can be transferred between planning and learning. In particular, in many cases a learning algorithm can be substituted for the key backup step of a planning method. Learning methods require only experience as input, and in many cases they can be applied to simulated experience just as well as to real experience.
- One of those ideas was that we might roughly consider "seeking" behavior to be positively valenced and "avoidance" behavior to be negatively valenced. This article includes statements that, to me, suggest the same basic idea:
since [the violence inhibition mechanism] VIM initiates a withdrawal response, he suggested that these moral emotions would be experienced as aversive. [...]
Mandler (1984) has claimed that the interpretation of arousal following an approach response results in the valancy of the consequent emotional state being positive.